I don't know if anyone around my age (those in their late 10's to early 20's) would have experienced enough of the early days of the Web 2.0 hype to remember this, but there used to be a protocol that all blogs should follow called RSS (RDF Site Summary, but officially short for Really Simple Syndication). Basically the idea was to create a standardized protocol for "Web 2.0"-based web logs – or "blogs", for short – to:
- provide a standardized way, based on XML, for people to subscribe and read blog posts people want to follow without having to visit every single blog to read invidivual posts from all authors they like; and
- provide basic standard communication between these blogs so that posts from different blogs would be able to reference one another, such that people will be able to read responses posted on other blogs from one blog post
The second feature was called RSS trackbacks, and was actually commonly used to either add thoughts to posts of another blogger or, more commonly, promote their own blog out of context from the original one – which eventually led to trackbacks being somewhat permissioned (i.e. bloggers only allowing trackback links they approve to appear on their posts as replies).
Initially RSS gained traction among most blog engines and services; WordPress, Drupal, Blogger, and many others had built-in RSS support. There are also a fair number of RSS reader applications where users could subscribe to blogs without even visiting these blogs one-by-one (Reeder being my favorite app). Windows even used to have built-in RSS support on Windows Vista or later. But nowadays no one really uses RSS extensively, and support for RSS have dropped significantly, especially after the mid-2010s, due to the following reasons:
- It makes more sense for someone to make a Google search and only read a blog post they want, or if they like their posts and want to follow up, follow them on Twitter, Facebook or Instagram to receive further updates on their feed. A decentralized protocol that requires W3C-level consensus for upgrades can't really catch up with these centralized services.
- RSS harms monetization and wasn't built with monetization in mind. As Google built its AdSense network and incentivized bloggers to add ads to their content for monetization, providing an RSS feed that can't serve AdSense suddenly didn't make sense for bloggers. RSS also blocks donation widgets – while technically you can add a hyperlink to a PayPal donation page on every RSS post, for example, it isn't as eye-catching as a dynamic widget. When Stripe first started to gain traction as widget-based paymets back in 2014, they were also widgets after all, and RSS couldn't support them either when bloggers wanted to paywall their posts with Stripe.
- People view more video content on the Web now (YouTube, TikTok, Instagram Reels, Netflix, etc) instead of static text. YouTubers and TikTokers have way more influence than bloggers simply because, well, reading text is boring. And what can you do about YouTube and TikTok taking over every single video on the planet when a text version for content interoperability already have failed?
The argument I am trying to make here is that enforcing interoperability on the Internet in general is incredibly difficult because what people want change all the time, and standards are simply too slow to catch up with these changes. RSS failed because it failed to catch up with changes – first with new monetization techniques with ads, and content shifting from text to video. I can also probably name a dozen other examples that went down the same path. Centralized services ran by companies that see this opportunity quickly fill in the interoperability gap (Google Search and Twitter replacing RSS feeds, for example), and that's how we ended up with the Internet we are used to today: less standardized protocols, more centralized control.
If we look at the Web 2.0-era protocols that did survive, they are more technical ones way down the stack than user-facing interfaces, like WebSockets and Ajax. And newly emerging standards of the Web are built by big tech instead of a standardized body, too: GraphQL, React, WebRTC, WebExtensions, Chromium, WebGPU, TypeScript, you name it (perhaps one of the few exceptions is WebAssembly (Wasm), but efforts on those was still led by Mozilla, a nonprofit foundation, instead of a standardized task force).
RSS was a natural example to start this post because I wanted to add this article as a trackback to Vitalik's new post, The Three Transitions, only to realize his website is static-built (because it lives on IPFS and ENS) and doesn't have RSS support; I found it ironic the solutions he is advocating for have a high probability of meeting the same fate. Not to say absence of RSS on his blog is a bad thing – it's unnecessary now and only adds bloat – but most of you would have found that exact post through Twitter instead of a protocol that was meant to solve content discovery in a decentralized fashion.
Tech is layered: market competition versus standardized protocols
From now on, I will assume all readers to have fully read Vitalik's original post. If you haven't, go read it now. It's an excellent read and gets you thinking about the current state of the Ethereum ecosystem, as well as efforts and challenges remaining associated with it.
In short, his problem diagnosis is correct: there are three conditions that needs to be met for blockchains to go mainstream, that is: better key management, better scalability, and better privacy solutions, and that scalability through multiple L2 rollups combined with ERC-4337 smart contract wallets is only making things a lot more complicated. Users will have one address per rollup (and chain) and have assets fragmented across these rollups; theoretically if you have assets across $n$ chains, you will end up with $n$ different addresses.
But I believe the direction Vitalik is trying to push everyone towards is wrong. In fact, regardless of how much work that have went into building all these cryptographic primitives and systems, they probably won't last long.
As a general critique, Ethereum is trying to do too much on the higher level of the technical stack – that is, the Ethereum blockchain and the EVM. More specifically, it seems like the general direction Ethereum is trying to head towards is that every logic and standard belongs onchain, and we need faster finality for these primitives because everything should be defined as a strict set of state transitions definable on either Ethereum, or a rollup of these state transitions posted on Ethereum.
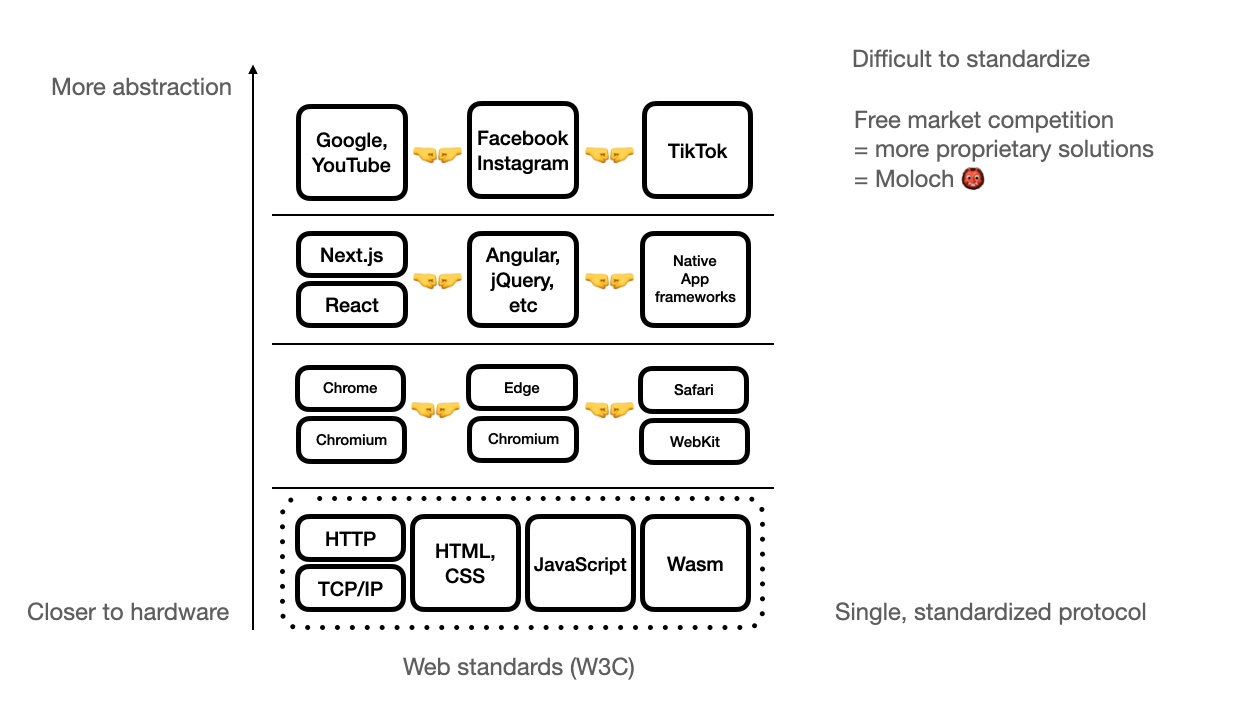
As I mentioned earlier, however, it was very rare for protocols trying to standardize things on the higher end of the end-user application stack to eventually gain mass adoption because of how quickly things change. You can't predict what the future might look like, and building a standard higher up means your protocol will become useless – or even looking at the best-case scenario, a technical legacy – when the next paradigm shift comes. TCP/IP, HTTP, SSL/TLS, HTML, CSS and JavaScript all survived multiple fundamental paradigm shifts and will continue to be the protocol we build upon for years to come, despite its design flaws (the fact that we are still relying on BGP that can kill off 30% of the Web from accessing services for a single fault propagation failure by an ISP is simply mind-blowing, but because it's way down in the technical stack no one dares changing it; the only major transition we have seen recently is the shift from TCP/IP to UDP with HTTP/3, which is a transition we have needed for mobile networks where we have spotty connections more often and don't need handshakes anymore in the first place).
On the other hand, protocols built on the higher end of the application stack trying to standardize what's directly connected with user experiences couldn't last long because, again, we don't know what's next and can't really futureproof them. RSS died because it couldn't catch up with how content distribution, monetization and type changed on the Internet for the last decade. YouTube, TikTok, Twitter, Instagram and Facebook took its place – which are all centralized services. They are built on the same low-level foundations and protocols that the Internet is based upon, and they too will die off once the tide turns once again. Even tech stacks sitting in the middle change all the time – anyone remember jQuery or Angular? Flash? Java applets?
Because of this, technical stacks that are more fundamental and down the stack (i.e. closer to bare metal) tend to be standardized much quicker, easier, and change way less often – future applications will also probably built on top of them. Those are what become long-lasting protocols. On the other hand, technical stacks that are higher up – i.e. closer to what's user-facing and more abstracted – are subject to change a lot more often than those that are lower. A paradigm shift from text to video, for example, deprecated a lot of concepts of "hypertext" originally proposed with the Web; it took the W3C more than a decade to standardize what Flash and Java applets have been doing for more than 20 years with video and interactive content with HTML5, and those are not even that far up the stack. When things are this unstable and quickly changing, it is less likely for them to be a standardized protocol and more likely to be proprietary services, simply because free market competition is way more efficient to responding to changes and paradigm shifts than protocols that require a long time to reach consensus.
That's how we came with the current state of the Internet: standardized protocols on the lower end, while solutions and applications becoming more proprietary and fragmented, due to market competition, as we go higher. Protocols we previously thought would be stable are even facing fierce competition from proprietary tech: email and CalDAV is slowly being subsidized with solutions like Slack, Discord and Signal, and what's remaining is becoming semi-proprietary with Google and Microsoft taking over most market share. SMS and MMS have been long outdated and it took the carrier industry more than a decade to properly respond to iMessage and other messaging contenders with RCS.
So if we want services on the Web to be more transparent and less data-hungry, it makes more sense to first think about which layer our solution is sitting at, and how it can force software and services being built on top to have certain properties. The reason why there are multiple blockchains out there is a natural result of this market competition: people think they can do better than Ethereum, at least from a business perspective, and take over that portion of the market where there is demand – whether it may be more centralized or be completely private. You may like it or not, but there always is and will be demand for these types of solutions.
That's why having account abstraction and rollups at the same time don't make sense: blockchains are closer to platforms than protocols, and it is safe to assume there always will be competition and fragmentation across the entire market. ERC-4337 relies on onchain logic to mimic wallet-like behavior so that wallets can be "programmable"; the issue with this approach is that, again, it sits way too far up the technical stack and is subject to fierce competition. Fragmentation of wallet addresses aren't even the core issue here because they are somehow solvable, let it be cryptographic pointers or ENS. The real issue is it can't compete with centralized competitors because of the fact that it is way too up the technical stack. Custodial solutions can move quicker and provide a better user experience than any solution smart contract wallets may be able to put together, especially under a multi-blockchain scenario.
The question is this: how can we enforce the values we believe in, while still being able to compete with potential proprietary solutions?
Enforcing identity
The answer is quite simple: build something that sits closer to the bottom of the stack, not the top. The closer to the bottom, the better, because we can:
- enforce the values we believe in to any product being built on top
- easily assume it would be futureproof regardless of what might come next
We need to be closer to raw hardware and base logic as much as possible, instead of trying to build everything on top of an abstracted layer. So where should we start?
A core problem no one have quite got it right on the Internet yet is authentication and identity. For one, we still rely on passwords for authenticating a user ID, combined with some fairly basic techniques like log-in location, 2FA, and periodic reminders to change your password every 6 months. Passwords have been around for more than 30 years, and still is the most widely used authentication method – other than FIDO hardware keys some organizations force their employees to use while accessing sensitive data.
Another problem is that humanity have almost developed an alternative identity on the Internet, separate from their real self, and yet there is no real way to establish trust on that identity. For one, there is no way to prove @alice on Twitter is the same person as @alice on Instagram if they are both not associated with a real photo or profile of a person. In short, there isn't a concept of a universal ID on the Internet unless you opt to log in with Google for every single service.
The first problem is being finally addressed thanks to mass adoption of Secure Enclave-equipped devices: FIDO2, or also known as WebAuthn, uses public-key cryptography with keys stored either on the cloud or on a hardware-backed Secure Enclave to facilitate logins instead of passwords. This has only become possible because there are now safer ways to manage PKI keys without forcing the user to deal with them, which is actually more dangerous than passwords (we can't even remember simple passwords for every single website). But this will take some time to adopt, and still doesn't really address the problem of not having a unified identification system across all web services. It only solves the issue of authentication itself.
Phillip Zimermann have tried to solve the second problem 30 years ago with the introduction of PGP: a "chain-of-trust" paradigm, where the assumption is – if enough people attest (sign) that this key, and all content signed and/or encrypted with this key, belongs to person $x$, then it must belong to person $x$. But it failed mostly outside of the cryptopunk community: the software was just too complicated to use for end users. Another attempt to revive PGP for the masses, Keybase, where one of its value propositions was that it can cryptographically link your social IDs to one key so that people can identify they are the same person, also failed to grab mainstream attention: they ended up getting acquired by Zoom in 2020 to work on end-to-end encryption for Zoom calls.
How does this tie into blockchains? Well, we were just talking about account abstraction being way too up the stack to compete with custodial solutions. The point of account abstraction was to allow one user to switch between different keys or even use different signing curves to authenticate onchain, such that the user won't have to remember seed phrases. But this is actually the exact same problem that existing web services are facing right now – matching devices with user IDs. So we can actually pinpoint the core problem to something much more down the stack: that it isn't possible, at least for now, to assign a single cryptographically recognizable signature across multiple devices that have nothing in common.
Account abstraction tries to avoid this problem by getting rid of signatures altogether and replacing all wallets with contracts, but this of course breaks compatibility with existing wallets, and any other solution that does not have smart contracts such as Bitcoin. This is a problem, as the foundation of blockchains is cryptography and we are no longer able to cryptographically associate someone across multiple chains and also loses compatibility for anyone outside of the blockchain ecosystem.
An ideal solution for this should satisfy the following properties:
- The solution should not involve cryptographically related keys. For example, there could be $n$ different keys able to produce a single signature $k$, but when we add another key that is completely unaware of the private keys of any one of $n$ and now we have $n+1$ keys, all of them should still be able to generate the same signature $k$ out of this new key $s$.
This leaves multisig, threshold signatures and MPC out of the solution list as their keys must be cryptographically derived from one another. - The solution should be able to handle multiple signature schemes. The system, for example, should be able to accept a list of EdDSA-based keys and generate an RSA-based signature.
- The solution should not be limited to blockchains or any particular system, it should be purely cryptographic such that it can be used for general authentication and signing of any existing application.
This allows for not only linking between accounts on different blockchains, but also accounts on any service that allows for PKI signing, like Git commits and signing email with PGP.
This also ensures the system could be used across any primitive, such that it would be futureproof for services that may be launched in the future.
Basically this is the $n$-to-$1$ key problem, where a set of $n$ distinct keys should be somehow associated with a completely unrelated key or signature. This is what we have been working on for the past few months, and we believe we have cracked this problem – we just need some additional testing.
But this applies for any primitive in general; we should always assume there will be more competition as we build on top of more abstracted systems, and proprietary systems are much easier to handle fragmentation at such a state than a single enforced to standard. And trying to enforce one abstracted system to everyone won't bring good, it will bring more fragmentation and give space for an even more centralized party to rise from that fragmentation.
Back to tech stacks: monopolies no more
Going back to abstracted environments giving way for more market competition and eventually monopolies, I also believe there should be a way to actually encourage competition – and, yes, at the cost of fragmentation – while standardizing the glue that lets them be interoperable to be built in the open.
Progress inevitably involves fragmentation and competition because otherwise there won't be incentives to improve upon what we already have. But at the same time, competition at levels where there should be open standards opens room for monopolies because of the fact that, as the industry matures, eventually people would want everything to be converged into one easy space where they can access everything at once.
There could be two ways to largely address this:
- Open organizations – organizations built on top of protocols that enforce openness, e.g. cryptography and blockchains, being the norm
The incentive to move from closed organizations to open organizations is to show that living and working on the Internet is actually better than traditional forms of organizations. If your business purely deals with software, for example, do you want to be limited to hiring people that you can find locally? Or would you rather be open to hiring people that may be anon, but you can trust are good, based on their existing contribution history? - Open software and services – software may not be fully open source, but at least they should be open – i.e. third parties should be able to assess what is going on internally. For example, serving ads in the open is miles ahead in terms of transparency than having a proprietary algorithm behind closed doors.
And we should also be able to persuade that this is a better way to build services! Having to install 15+ apps just to call a cab for every different country is very ineffecient compared to having a single layer of software handle things under an agreement, and is better for both customers and drivers because having transparent data encourages competition between these "clients".
To build this, we shouldn't assume that everyone will use a single software solution by default. We should build protocols that cover as many use cases as possible, and that's how we move forward with promoting protocols over services. $\blacksquare$